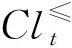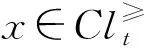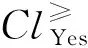刘力凯 李建林 刘金林
1(南京信息职业技术学院 江苏 南京 210023) 2(扬州大学 江苏 扬州 225002)
随着社会的发展与科技的进步,信息已从TB量级跃升至PB量级。数据中高效的知识发现需要突破传统数据挖掘仅能获取单粒度知识、表达力弱、知识黑箱和效率低下等问题的局限。针对多源异构、海量动态的复杂数据,通过复杂问题的多粒度思维模式,运用不确定性知识发现的粗糙集近似逼近理论,构建多粒度粗糙集知识发现模型,建立渐进式粗糙集知识发现方法对于大量需求分析研究显得十分重要。
在该背景下,本文以优势关系粗糙集为理论工具,借助优势关系粗糙集从知识本身发现规律、规则的可解释性和以确定的方法研究不确定性问题等特点,将数据转化为优势粗糙集决策表,采用对象粒化的思想将计算对象粒化,从而方便数据处理,并从中提取有效信息。
粗糙集理论[1](Rough Set Theory)由Pawlak教授于1982年提出,作为一种刻画不完全、不确定的数学工具,其依据统计和推理从数据自身发现知识,不需依赖任何先验知识,能有效地处理不精确、不一致和不完整等各类信息,以精确的手段处理不精确的问题,从中发现隐含知识,揭示潜在规律。优势关系粗糙集[2](Dominance-based Rough Set Approach,DRSA)由Greco等[3]提出,可以认为经典粗糙集属于其特例。作为一种数据挖掘工具,优势关系粗糙集同样根据统计和推理从数据本身推导知识,同时能有效处理属性间的偏序关系,能很好地处理不一致和不完备信息[4-5]。
针对优势关系模型中下近似求解过于严格,同时上近似求解过于宽松的现象,可变精度优势粗糙集[6](Variable Consistency Model of DRSA,VC-DRSA)使用DOMLEM算法[7]解决了问题,算法生成if-then类型知识规则[8],利于领域专家对所获知识进行理解和分析,并能解决规则冲突问题,其有效应用于决策分类[9],已在属性约简[10-11]、多指标排序[12]、疾病风险评估[13]、评价方法研究[14-15]、航空顾客行为预测[16]、故障诊断研究[17]和移动用户换机预测[18]等诸多领域实施了广泛的应用[19]。
数据不一致性可由数据边界的犹豫性和数据采集过程中的人为错误、数据缺失等因素造成。在实际应用中,不一致对象的存在限制了更多的对象进入粗糙集下近似,不利于决策规则的提取。传统优势关系粗糙集在处理不一致对象时往往有一定的局限性。Greco等[6]研究了一种基于包含度的变精度优势关系粗糙集方法模型,但是它不能有效地处理由于异常数据带来的不一致性。针对这种情况的不足,Inuiguchi等[20]研究了一种基于支持度的变精度优势关系粗糙集(Variable-Precision DRSA, VP-DRSA)方法模型,但它不能有效地利用边缘对象的信息。为了使决策表提供的有益信息得到充分利用,包含更多的数据对象信息,需要对模型处理不一致对象的能力来做进一步研究。
本文在分析已有优势关系粗糙集方法模型处理不一致信息局限性的前提下,研究了一种基于纠缠关系的优势关系粗糙集方法模型,其通过优势关系将属性相似、功能近似的对象进行整合,构建复杂的对象实体,并通过数据实验验证了该模型对于消除不一致对象影响的有效性。
为了便于叙述, 引入一些关于优势关系粗糙集方法模型的基本理论[2-3,21]。
定义1决策表信息系统。设S为决策表信息系统,S=
定义2优势关系。令≥代表论域U中的弱偏好关系,则x≥qy表示x在条件属性q上至少与y一样好,即x不差于y。优势关系定义为DP:P⊂C,∀x,y∈U,xDPy。如果q∈P,则x≥qy。
定义3上并集和下并集。将论域U通过决策属性D划分为集合Cl,有Cl={Clt,t∈T},T={1,2,…,n},则∀x∈U,x仅能属于某个分类Clt,Clt∈Cl。上并集的定义为:
(1)
对任意r,s∈T,如果r>s,可知Clr集合内的元素均优于Cls集合内的元素。下并集的定义为:
(2)
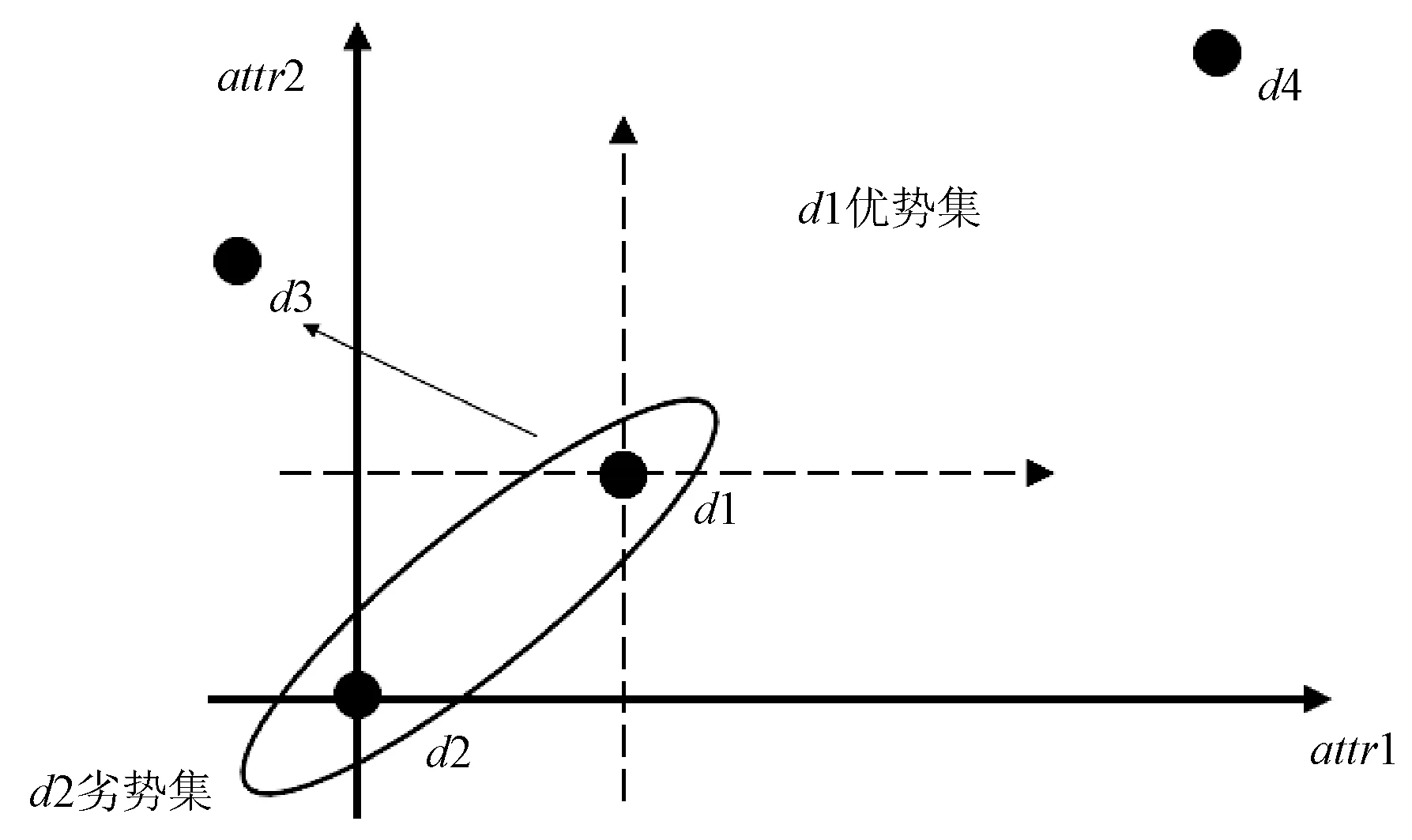
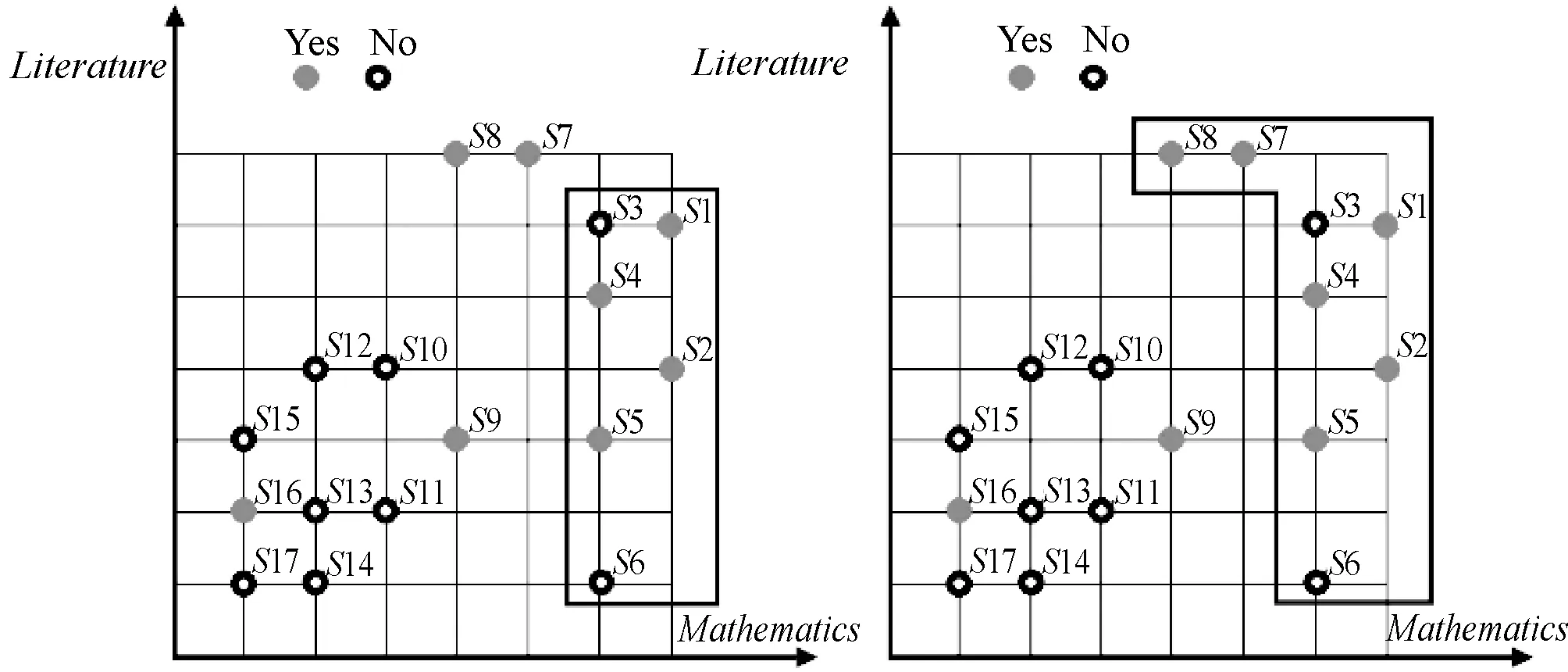
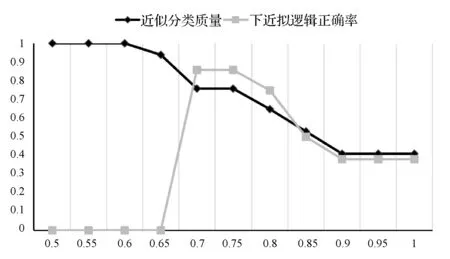
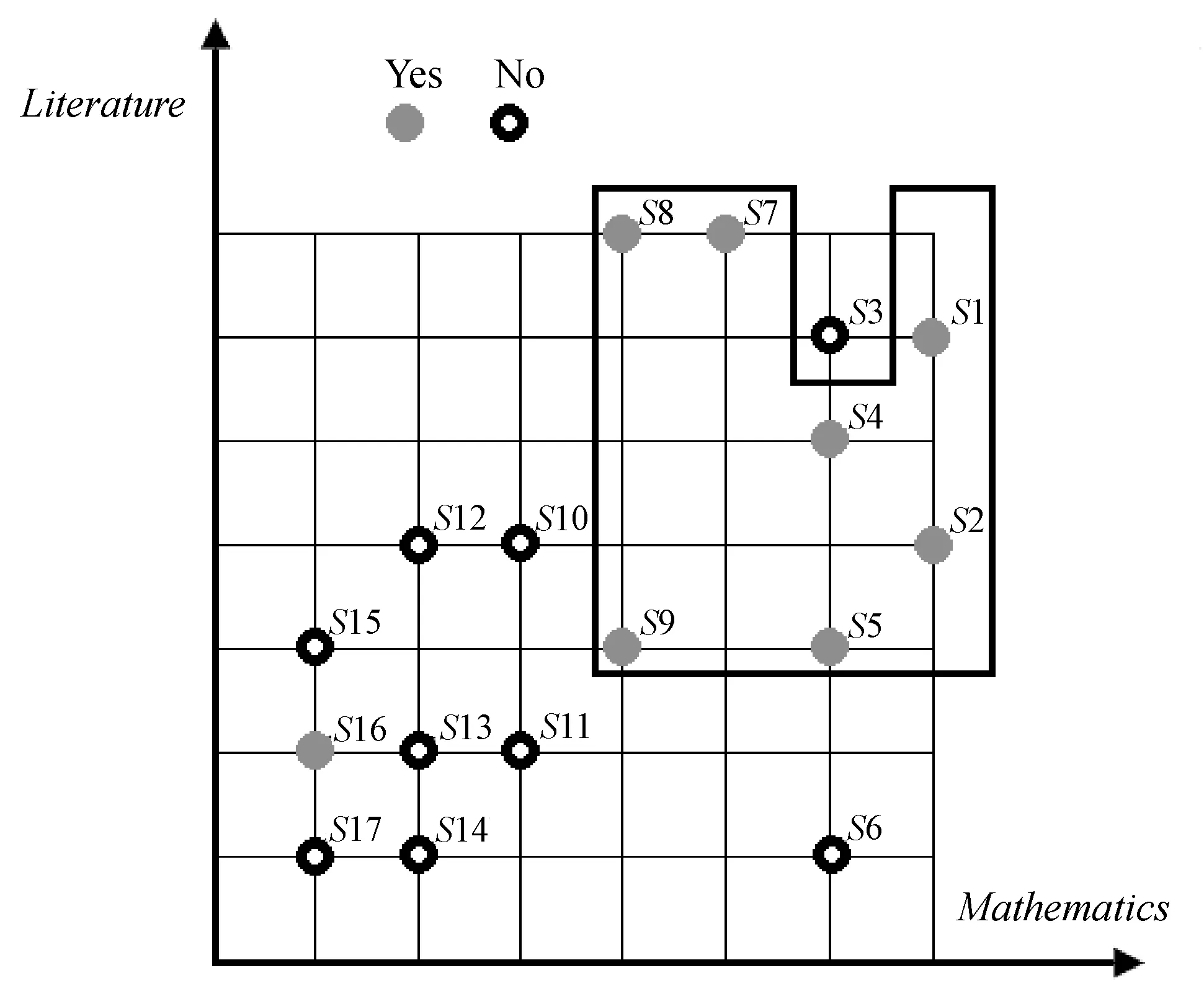
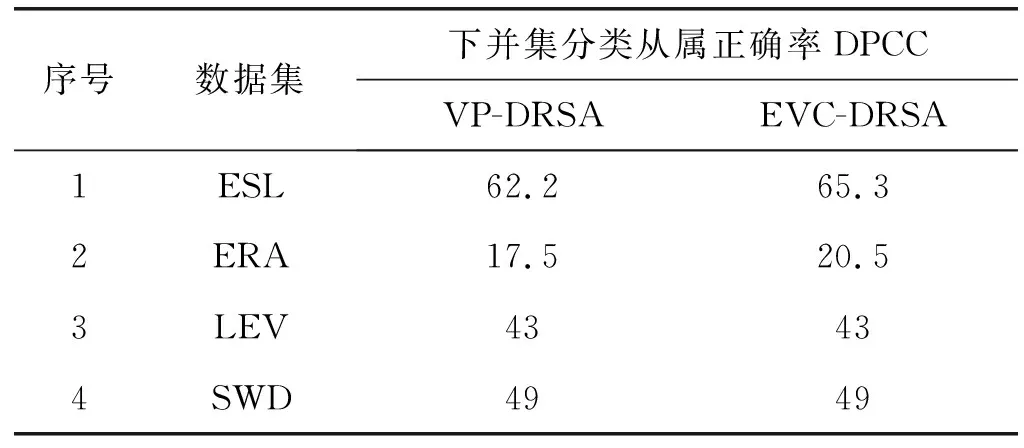
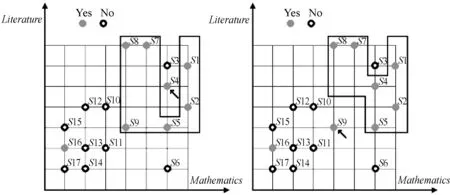
对任意r,s∈T,如果r 定义4优势集和劣势集。对于任意P⊆C,x∈U,y∈U,优势集的定义为: (3) 劣势集的定义为: (4) 定义5上下并集的下近似、上近似和边界域。上并集下近似的定义为: (5) 上并集上近似的定义为: (6) 上并集的边界域的定义为: (7) 下并集下近似的定义为: (8) 下并集上近似的定义为: (9) 下并集边界域的定义为: (10) 定义6VC-DRSA模型的可变精度上下近似。可变精度的上并集下近似定义为: (11) 可变精度的下并集下近似定义为: (12) 式中:l为变精度参数,由人为设定。 定义7VP-DRSA模型的可变精度上下近似。可变精度的上并集下近似定义为: (13) 可变精度的下并集下近似定义为: (14) 定义8近似精度和近似分类质量。上并集近似精度定义为: (15) 下并集近似精度定义为: (16) 近似分类质量定义为: (17) 传统优势关系粗糙集中,如果需建立两个样本之间的优势关系,必须要保证某个样本在所有属性上比另一个样本好或者差。但这种关系过于严苛,忽略了在某些属性上好而另一些属性上差的样本。另一方面,虽然进入优势集或劣势集的样本之间统计意义一样,但好一点点的样本和好一个数量级的样本同样进入当前样本的优势集合,它们与当前样本的联系和所带来的有效信息却大不一样。 如表1所示,这是一张包含学号、数学成绩、文学成绩和通过情况的学生评价决策表,其构成一个不一致决策表信息系统,其中包含不一致对象信息。 表1 学生评价决策表 求解求解图1 模型下近似求解 通过多组实验及调整一致性水平l发现,VC-DRSA对于处理边缘犹豫数据较好而处理样本异常点时存在不足。而VP-DRSA对于处理样本异常点较好而边缘犹豫数据存在不足。 针对VC-DRSA和VP-DRSA模型对于异常点和边缘犹豫数据处理的不足,本文提出了一种基于纠缠关系的变精度优势关系粗糙集(Entangled Variable Consistency Model of DRSA, EVC-DRSA)。为了充分考虑这些不能进入优势集或劣势集的样本带来的影响,同时对不同优劣数量级的样本加以区分利用,本节从粒计算的角度提出了一种数据纠缠关系,并以此为基础提出一种基于纠缠关系的变精度EVC-DRSA模型。 在传统优势关系粗糙集中,严格具有优势关系的样本,才可相互进入优势集或劣势集,见式(3)和式(4)。但这种关系过于严苛,当存在不一致数据时,忽略了在某些属性上好而在另一些属性上差的样本,这些样本间则不能建立联系,从而影响了上、下近似的求解精度。另一方面,进入优势集或劣势集的样本虽然在统计上一样,都增加了优势集或劣势集对象的个数,但实际上它们是有区别的。以优势集为例,好一点点的样本和好一个数量级的样本同时进入当前样本的优势集合,在统计上它们是一样的,但实际上与当前样本的联系紧密度却大不一样。 为了充分考虑不一致信息带来的影响,本文提出了一种数据纠缠关系,以两个属性的数据为例,数据间的纠缠关系如图2所示。 图2 数据的纠缠关系演示 图2中有四个二维数据样本d1、d2、d3和d4,坐标值越大代表此样本在相应属性上表现越好。通过观察可知,d3在attr2属性上比d1好,即d3≥attr2d1,d3在attr1属性上比d1差,即d1≥attr1d3,则d3和d1无法确定优势关系。同样,d2≥attr1d3,d3≥attr2d2,d3和d2也无法确定优势关系。此时,对于样本d3而言,d1和d2进入了d3的不确定域。 定义9元素的不确定域。对于x∈U,定义x的不确定域Sx为: Sx=U-D+(x)-D-(x) (18) 元素x的不确定域为论域中不能进入元素x优势集和劣势集的对象集合,即无法与元素x确定明确的优劣关系的对象集合,Sx中的元素在某些属性上比x好,其他属性比x差。 对于图2中的数据,由于d1和d2均进入了d3的不确定域,d1和d2在d3的不确定域中地位相等,因此当d3作为观察样本时,导致了d1和d2在某种程度上的不明朗,从d3的角度无法推断出d1和d2之间的直接关系,则约定d1和d2是相互纠缠的。另一种情况,不存在观察样本使得d1和d4同时进入该样本的不确定域,因此d1和d4不存在数据纠缠关系。在实际中,具有数据纠缠关系的样本点之间联系更加紧密。 一般的,对于数据样本x和y,如果存在观察样本q,使得x和y均进入了q的不确定域,则称x和y是外部不可分辨的,从而定义x和y具有数据纠缠关系。论域U上和x具有数据纠缠关系的元素构成的集合,定义为x的纠缠域。 定义10元素的纠缠域。对于x∈U,定义x的纠缠域Qx为: Qx={y∈U:Sx∩Sy≠∅}∪x′ (19) 元素x的纠缠域为论域中对象的不确定域与x的不确定域有交叠的元素集合。x′为x的克隆对象,其意义是x与其本身是纠缠的。对于∀x∈U,约定当所有Sx∩Sy=∅,x≠y时,Qx∈U=U,因为不存在特殊的非克隆对象对任意x有特殊的作用,即约定整个论域中的元素都纠缠在一起。元素x纠缠域中的所有元素与x的关系均不明朗。以表1学生评价决策表为例,S1和S3的纠缠域分别如图3(a)和图3(b)的框内所示。 (a) 对象S1的纠缠域 (b) 对象S3的纠缠域图3 对象纠缠域 在图3(a)中,QS1={S1,S2,S3,S4,S5,S6},其构成S1的纠缠域。因为存在观察样本S7或S8,使得S1与QS1内任何元素都同时进入S7或S8的不确定域,导致外部不可分辨关系发生,所以S1与QS1内任何元素都具有数据纠缠关系。 (20) (21) 由于上下近似的互补性,进一步可以得到: (22) (23) (24) (25) (26) (27) 求解纠缠关系的变精度DRSA模型的上、下近似集过程可以看作是一个粒度计算[22-23]过程,它将信息按其特征和性能划分为不同的粒度,元素的纠缠域和非纠缠域可以看作是不同的粒划分,受元素所处环境不同导致纠缠域不同,相当于粒化的程度不同。不同元素的不同纠缠域可以看作不同的粒层次。 定义12近似分类质量。决策表信息系统近似分类质量定义为: (28) 令P=C,l取最合适值,如图4所示,可知VC-DRSA的一致水平l=0.75时效果最好。如图5所示,EVC-DRSA的一致水平l=0.75时效果最好,VP-DRSA的一致水平l=0.75时效果最好。 图4 VC-DRSA一致水平参数l取值实验 图5 EVC-DRSA一致水平参数l取值实验 图6 EVC-DRSA模型求解结果 为了验证EVC-DRSA模型的有效性,我们设计了如下的对比实验。由于在数据集特性未知情况下,认为由异常点造成的数据不一致性比犹豫数据造成的数据不一致性更加难以容忍,因此分别测试VP-DRSA模型和EVC-DRSA模型的下并集分类从属正确率,使用VC-DOMLEM规则提取算法提取决策规则,选用ERA、ESL、ELV和SWD这4个数据集[24]。其中ESL数据集不一致性程度较高,ERA、ELV和SWD数据集不一致性极高,很好地符合了不一致信息系统决策规则的分析提取要求。 根据定义1可知ERA、ESL、ELV和SWD这4个数据集分别构成4个决策表信息系统,其中每个信息系统的条件属性集合C都由多个元素qx构成。对于论域U中的每一条记录d,将它们按照决策属性D对论域U的划分进行优势排序,在最理想的预期下,di和di+1应该有严格的优势关系,即对于∀q∈C,一定有di≥qdi+1或di+1≥qdi,且这种关系在∀q上保持一致。在实际数据集中,由于各种原因总会造成不一致信息的存在,造成数据之间并不存在严格的优势关系,di≥qdi+1或di+1≥qdi将被打破,此时结合定义9,总会存在某个元素x,使得x的不确定域Sx≠∅,从而可以建立数据间的纠缠关系,并通过定义10求解出x的纠缠域。 为了达到实验结果的客观要求,本文采用5重交叉验证法,随机将数据平均分成5份执行5次循环,在第i次循环中取其中第i份(1≤i≤5)作为测试集合,剩下的4份作为学习集合,取最高的实验结果作为最终实验结果,以下并集分类从属正确率(DPCC)作为衡量。VP-DRSA模型的一致水平设为0.75。EVC-DRSA模型的一致水平设为0.75。测试结果如表2所示。 表2 模型EVC-DRSA有效性测试(%) 由表2可知,在LEV、SWD数据集上EVC-DRSA下并集分类从属正确率与VP-DRSA相等,ESL和ERA数据集效果较好,验证了EVC-DRSA模型的有效性。 数据中有大量不一致数据存在,现有的变精度DRSA模型对处理异常点和边缘犹豫数据带来的不一致性存在局限性。本文通过优势关系设计了一种基于纠缠关系的DRSA模型。其将属性相似、功能近似的对象进行整合,构建复杂的对象实体,充分考虑了不能进入优势集和劣势集元素对当前样本的影响,同时建立纠缠域区分了不同元素对求解下近似的影响,将仅在统计上对求解产生影响,但实际联系不紧密的元素排除,从而去除该部分包含的不一致对象,达到不一致对象消除的目的。在今后研究中,可建立基于数据驱动的自主式动态学习方法,以减弱先验知识在知识获取中的依赖,例如变精度DRSA模型一致水平参数的确定需要对其进行遍历实验。因此,如何通过数据本身确定参数的取值,从而简化实验过程、强化不一致信息在处理中的适应性,显得十分重要。
2.1 VC-DRSA模型的分析

2.2 VP-DRSA模型的分析
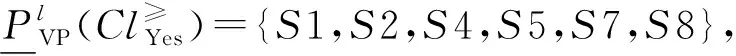
2.3 EVC-DRSA模型